oracle-rac-主机异常重启之后其中一个节点无法正常启动
前言
记录一下之前遇到的主机重启之后 rac 其中一个节点无法正常启动排查处理的过程,方便后续查询。当初还是第一次在云上部署和维护 rac,所以记录一下。也没有 MOS 账号,所以只能自己查找解决方法 😂
当初还是太年轻,经验欠缺,先入为主
环境信息
os:阿里云 ecs centos7.6 (Linux version 3.10.0-1160.71.1.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Tue Jun 28 15:37:28 UTC 2022)
oracle:11204 双节点
存储:asm 使用 oracleasm 配置
搭建集群时禁用了 haip。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
## 集群日志
cd $ORACLE_HOME/log/$node/
[grid@rac2 +ASM2]$ pushd $ORACLE_HOME/log
/u01/app/11.2.0/grid/log /u01/app/grid/diag/asm/+asm/+ASM2
[grid@rac2 log]$ ls
crs diag rac2
[grid@rac2 log]$ cd rac2/ ## 关键错误日志 alertrac2.log
[grid@rac2 rac2]$ ls
acfslog acfsreplroot admin alertrac2.log crflogd crsd ctssd diskmon gipcd gpnpd ohasd srvm
acfsrepl acfssec agent client crfmond cssd cvu evmd gnsd mdnsd racg
[grid@rac2 rac2]$
SQL> show parameter diag
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
diagnostic_dest string /u01/app/grid
SQL> Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Real Application Clusters and Automatic Storage Management options
[grid@rac2 rac2]$ cd /u01/app/grid/diag/
[grid@rac2 rac2]$ ll agent/
total 8
drwxrwxrwt 6 root oinstall 4096 Jul 16 2022 crsd
drwxrwxr-t 6 root oinstall 4096 Jul 16 2022 ohasd
[grid@rac2 rac2]$ ll agent/ohasd/
total 16
drwxr-xr-t 2 grid oinstall 4096 Dec 26 10:59 oraagent_grid
drwxr-xr-t 2 root root 4096 Jul 16 2022 oracssdagent_root
drwxr-xr-t 2 root root 4096 Jul 16 2022 oracssdmonitor_root
drwxr-xr-t 2 root root 4096 Dec 23 22:57 orarootagent_root
[grid@rac2 rac2]$
现象
应用测反应发现其中节点二服务器发生异常重启,无法正常启动节点二。
节点一日志提示和节点二通信超时:此时因为节点二正在发生重启,所以网络出现异常,后续查看日志发现在靠前的时间已经出现异常,集群尝试将节点二踢出集群。
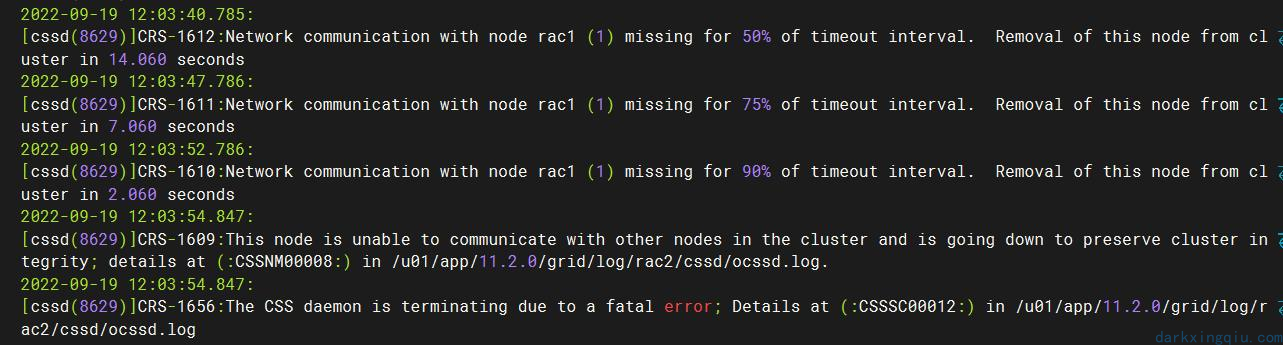
节点二发生重启:

此时集群只有一节点能够正常运行:
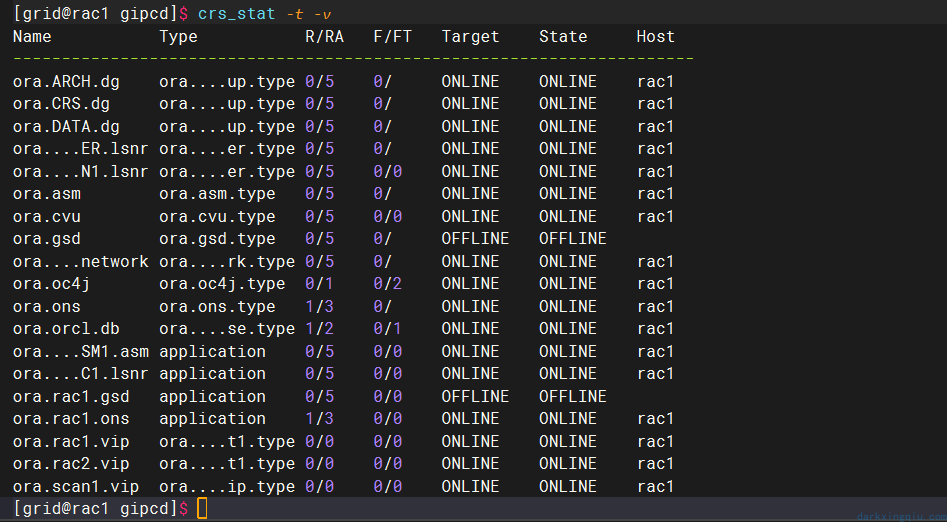
节点二无法正常启动:

处理
尝试重启节点二集群服务:
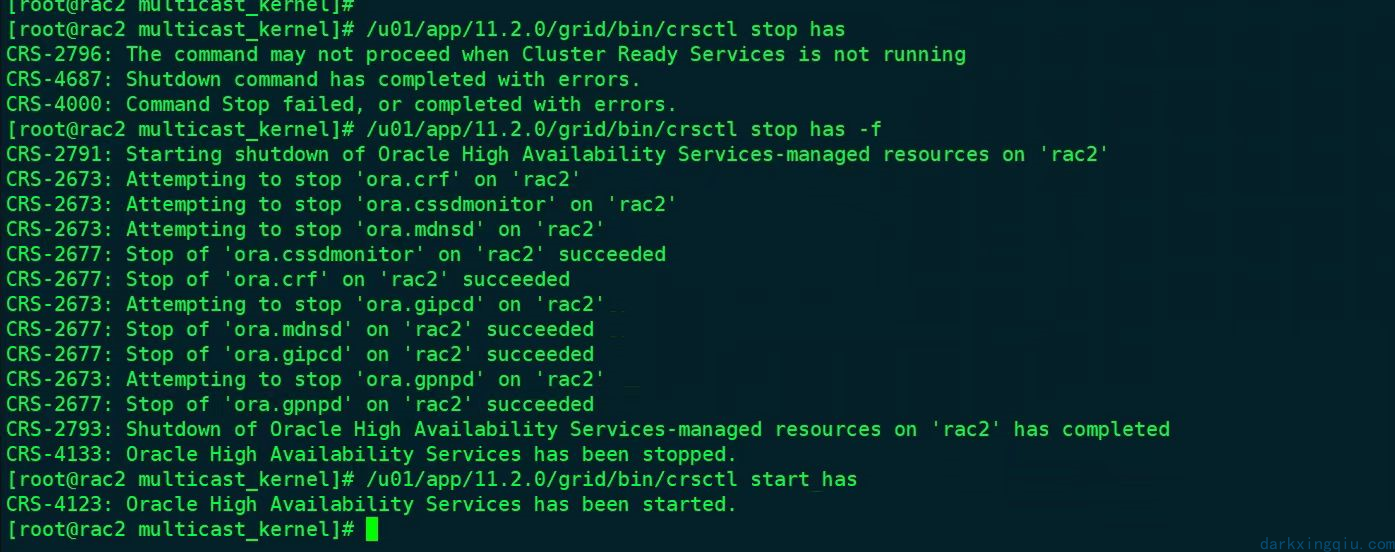
集群无法正常启动,此时怀疑是网络问题,因为最初在没有查看日志之前根据之前应用测发的集群日志信息,存在提示网络异常,所以首先检查网络情况。
发现网络能够 ping 通,但是使用 ssh 测试私网和 vip 时,提示需要将身份信息先保存,类似显示如下。怀疑之前配置互信之后没有做过登录验证,所以提示该信息。

重新验证互信之后,再次尝试重启,还是无法正常重启。检查时间以及 Oracle 文件和磁盘组的权限正常。
查看 os 日志发现时间存在异常:机器重启前后都存在时间不一致的问题,主机重启之后日期正常。排除时间问题。

因为 os 异常重启,所以最开始侧重检查 os 方面的问题,但因为是 ecs,所以无法查看底层信息,提交阿里工单咨询,回复说 ecs 的底层宿主机没有异常。
再次尝试重启节点二,此次重启是为了查看定位异常的集群资源:发现在启动 cssd 的时候卡住,可以使用 crsctl status res -t -init查看集群初始化的资源。
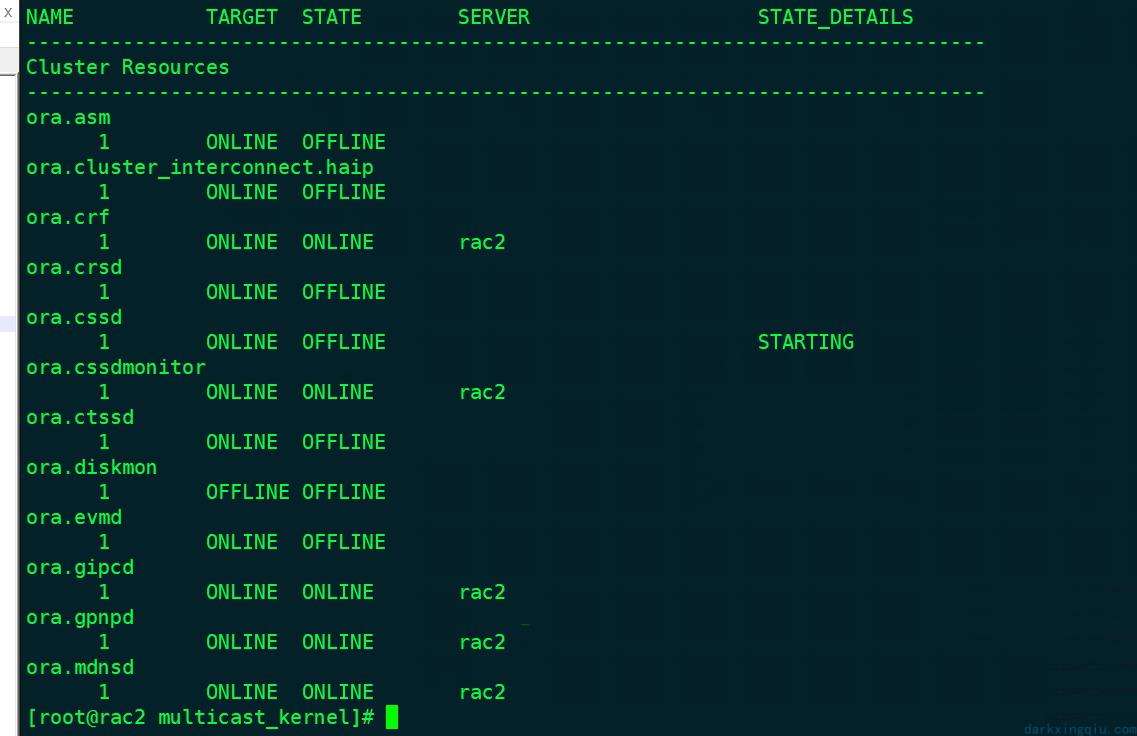
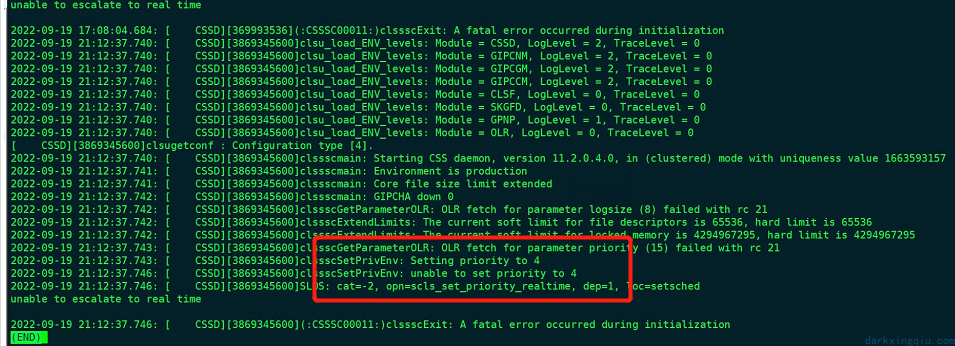
发现 ora.cssd 服务一直处在 starting 状态,查看 cssd 日志:可以发现 cssd 因为无法正常获取到 cpu 的调度优先级,所以无法启动。在解决这个问题的时候,被陷入为主的思想影响了。因为最初搭建的时候在启动集群资源的时候也会有这个错误提示,尝试使用当初的方法避免。发现并未解决。
在尝试之前的方式没有效果之后,认为是其他原因。继续排查,查看集群 alter 日志:发现 asm 也存在问题,接着排查 asm。
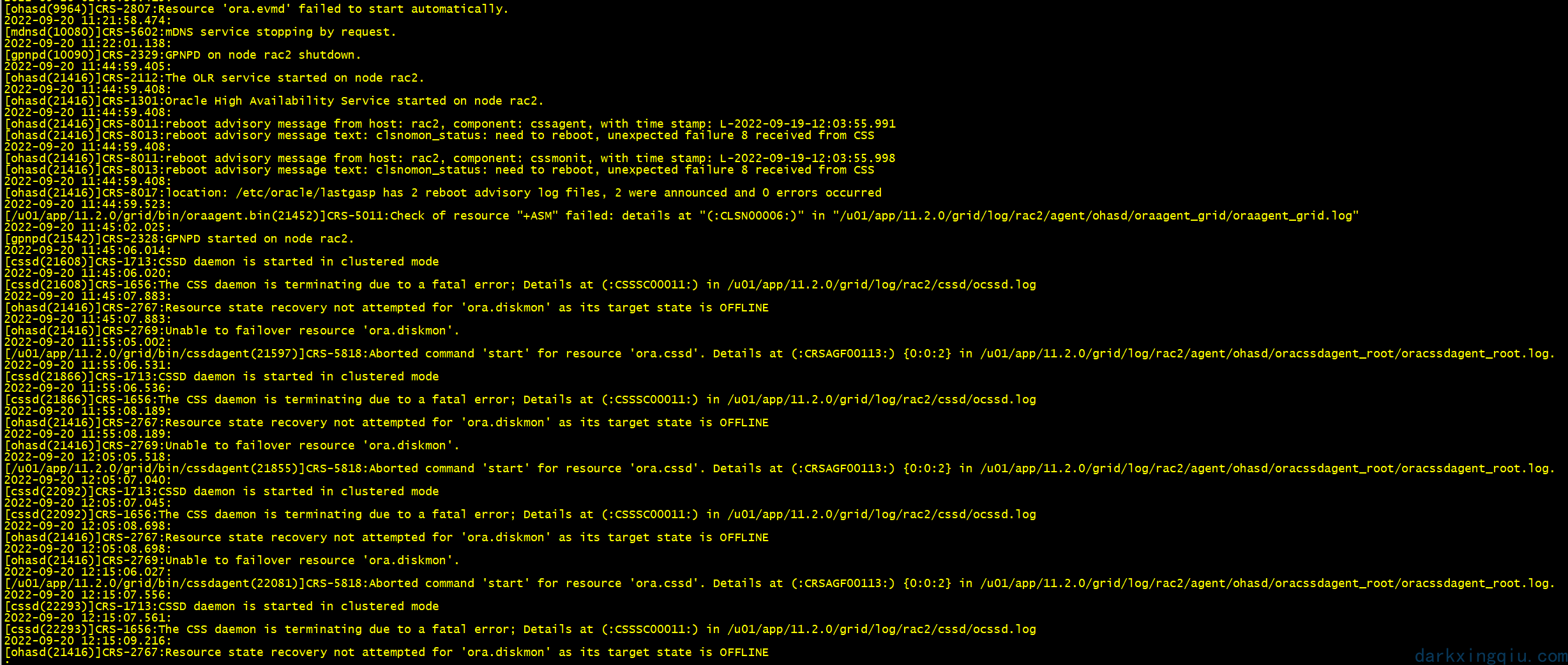
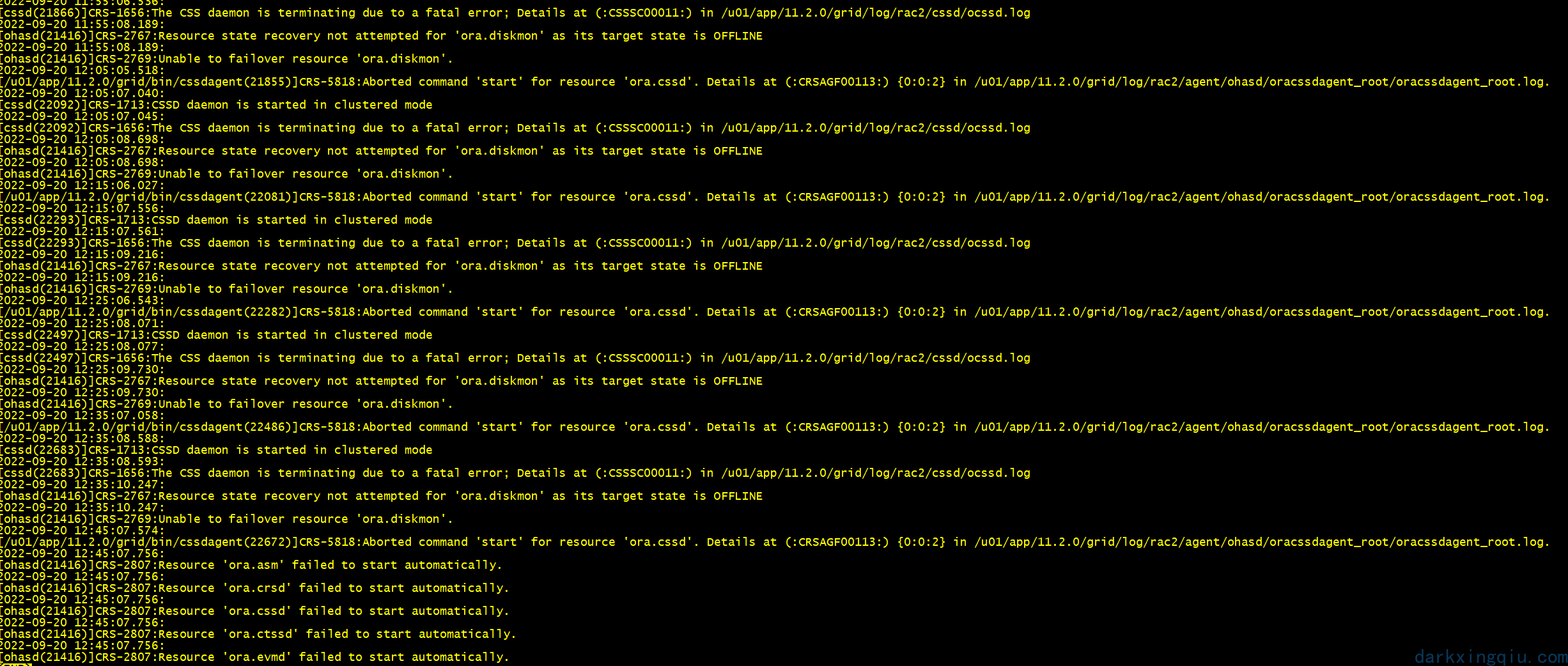
尝试手动启动 asm:此时再次怀疑私网和磁盘组权限问题。再次检查确认并无异常。

查看 cssd 日志,检查是否有网络异常提示:发现在节点重启时出现网络错误提示,但服务器启动之后并没有对应提示。暂时排除网络原因。

最后还是将重点放在了 cssd 服务上面:
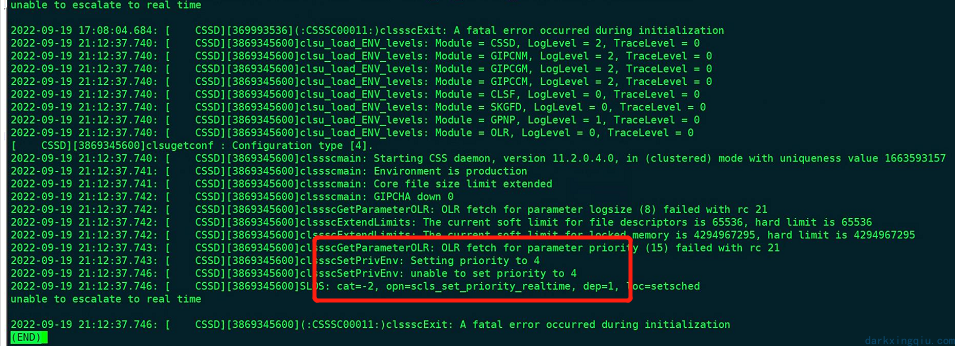
一般此种情况是因为 cssd 服务在启动时无法争取获取调度优先级,有些监控进软件(例如 splunk)会一直占用调度优先级,导致 cssd 无法获取优先级启动服务。
使用如下语句排查是否存在对应的监控软件:并无输出结果,因为 ecs 一般都会有一些监控资源信息的进程,虽然没有输出,但还是持怀疑态度。
1
find /etc/systemd/system.conf /etc/systemd/system /usr/lib/systemd -type f | xargs grep -e CPUAccounting -e CPUWeight -e StartupCPUWeight -e CPUShares -e StartupCPUShares -e CPUQuota |grep -v -e :# -e "^Binary file"

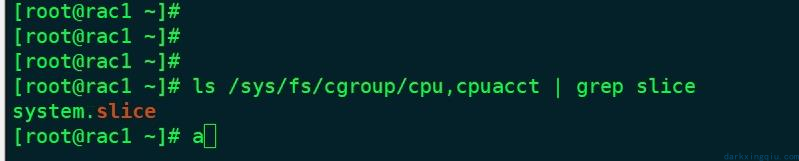
检查 cpu slice 情况:正常应该是没有输出的,节点一和节点二都有输出,但是节点二相较于节点一更多
1
ls /sys/fs/cgroup/cpu,cpuacct | grep slice

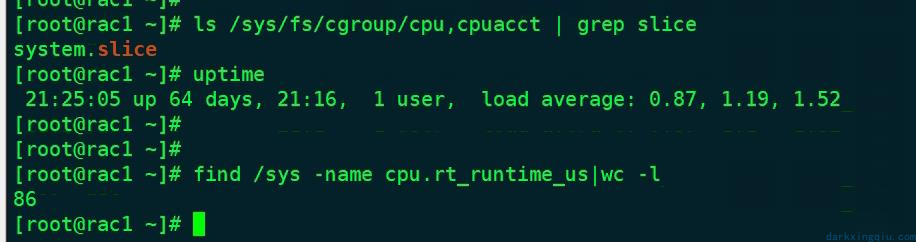
检查系统调度优先级的进程数量:两个节点都有输出,正常应该为 1。尝试重启节点二服务器,之后检查输出结果还是大于 1.
1
find /sys -name cpu.rt_runtime_us|wc -l

1
2
egrep -ri "^(Startup)?CPU.*=(.*%|1|yes|true|on)" /usr/lib/systemd/system /etc/systemd/system
##两个节点没有输出结果 正常
至此基本确定 cssd 无法获取 cpu 调度优先级导致集群无法启动:解决办法如下。
当 cssd 无法获取 real-time 优先级并且运行在非 real-time 优先级时,可能会引发各种异常。因此从 19c 开始,cssd 无法获取 real-time 优先级被当作一个致命的错误。如果 cssd 无法获取 real-time 优先级,则无法启动。
- 修改/etc/systemd/system.conf 文件参数,再次重启集群,发现 cssd 还是无法启动
1
2
3
4
vim /etc/systemd/system.conf
DefaultCPUAccounting=no ##将此行取消注释 然后重启
shell> shutdown -r now
- 尝试修改内核参数kernel.sched_rt_runtime_us = -1 ,再次重启集群,集群正常启动。至此集群故障处理完成。
1
2
3
4
5
vim /etc/sysctl.conf
## 添加一行
kernel.sched_rt_runtime_us = -1
sysctl -p ## 是参数生效,也可以直接重启服务器
建议在集群能够正常启动运行之后,将参数修改为默认值 950000。避免后续存在异常的进程,一直持有 cpu 调度优先级,引发其他影响
参考链接:
MOS:
Doc ID 2775091.1
Doc ID 2870136.1
Linux: GI OCSSD Fails to Start After cgroups Setting Change (Doc ID 1577784.1)